One of the first things I automated via a program was determining results on the treasure table.
There is a fair about of rolling to determine treasure. There is also several sub-tables that
you could possibly have to roll on, multiple times.
Here is an excerpt of the treasure table from
Hyperborea
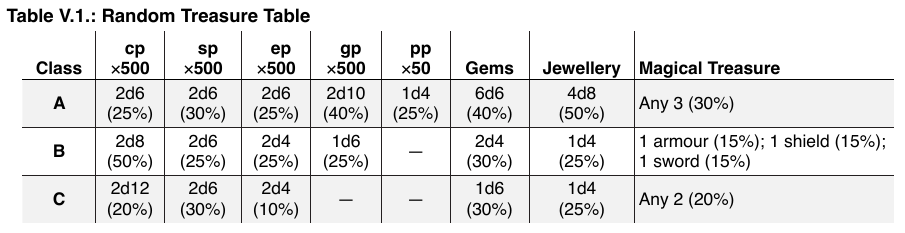
Let's use Treasure Class A as an example. This is probably the most rolling you
have to do. Determining coin results are easy. Things get more tedious if there are sub-tables.
Gems, Jewelry, and Magic have plenty of sub-tables to handle.
Here is the gems table.
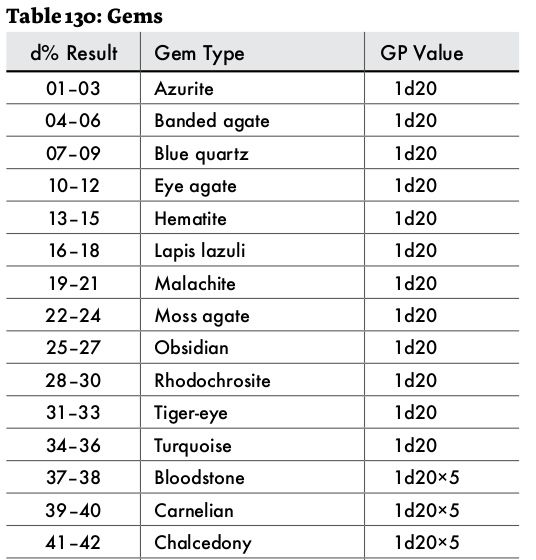
You can even do more rolling if you get the correct result.
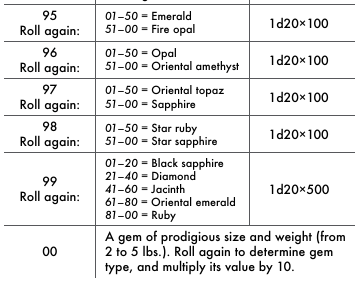
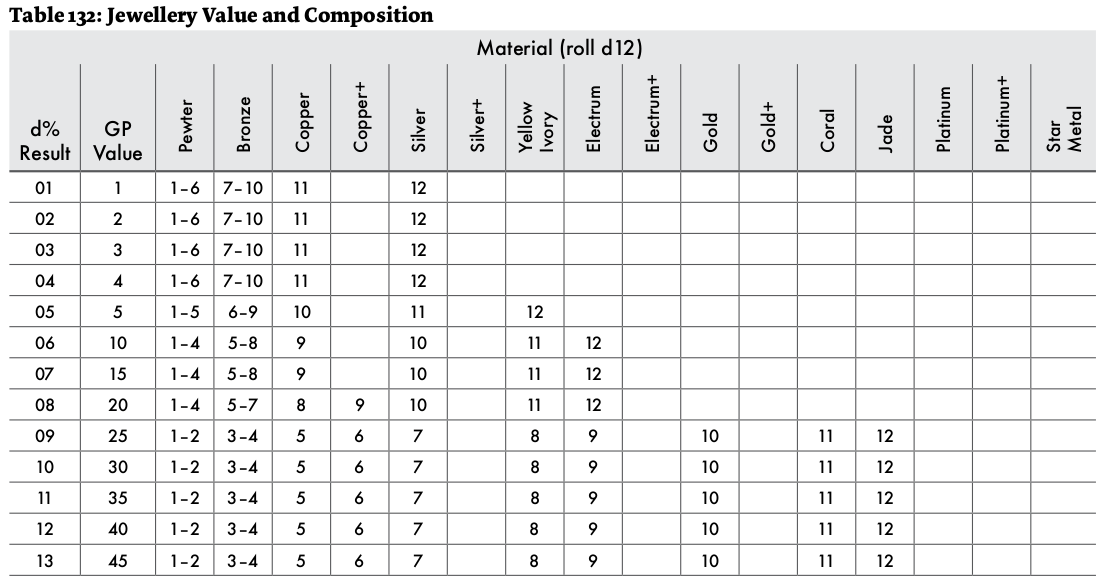
Jewellery has at least 2 sub-tables to roll on. The kind of jewellery.
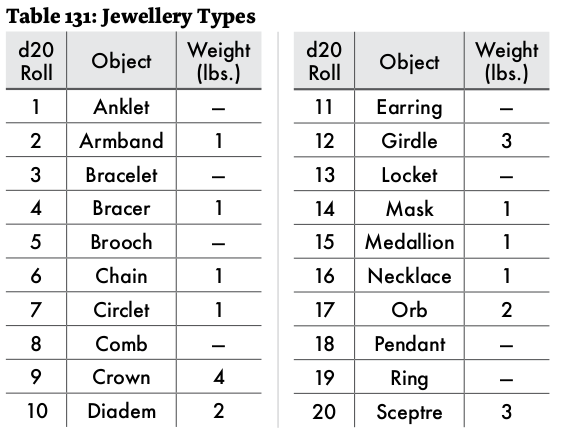
And what it is made of and it's worth.
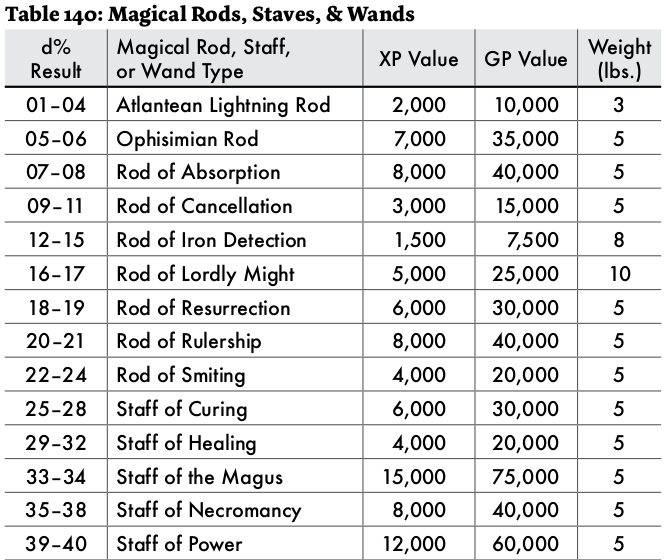
This is just the beginning for magic items. A veritable rabbit hole to go down.

It can end after a couple tables.
Eventually you get to the far end of that tree and have to come back for more rolls as needed.
Thankfully, the DM for a game I was in, and Perl Pumpking for some time, also seemed to have
a thing to automate tables.
There are lots of tables that can be referenced by a DM. So Rik Signes created Roland to help with automating the rolling on them
https://rjbs.manxome.org/rubric/entry/2013
Go ahead, give it a read. Rik does a good job explaining Roland. This post will be here waiting for you when you are done.
It's not available on CPAN just yet, but I'm working on him. He's says it's bad software but I think it works just fine.
Thankfully Roland can make all that rolling and referencing automated. That is
assuming you are comfortable with the level of entropy and randomness a pseudo
random number generator can give you
Really, go read Rik's blog post and then come back here when you are done.
Here is an example of the output of the program I created.
$ ./roll_treasure a
3500 cp
8000 gp
50 pp
10,000 gp piece of jewelry
5,000 gp piece of jewelry
100 gp piece of jewelry
750 gp piece of jewelry
1,000 gp piece of jewelry
200 gp piece of jewelry
100 gp piece of jewelry
100 gp piece of jewelry
200 gp piece of jewelry
100 gp piece of jewelry
500 gp piece of jewelry
200 gp piece of jewelry
200 gp piece of jewelry
200 gp piece of jewelry
Staff of Withering
Potion of Delusion (cursed)
Quarterstaff +2
The program itself, when stripped down, is really quite simple.
my @rolls = @ARGV;
for my $roll ( @rolls ) {
$roll =~ s/,| +|[()]//g;
$roll = lcfirst $roll;
my $count = 1;
if ( $roll =~ m/\wx\w/ ) {
($roll, $count) = split('x', $roll);
}
my $path;
my $roll_length = length($roll);
if ( 1 == $roll_length ) {
$path = qq(treasure/class_$roll);
}
else {
$path = qq(treasure/$roll);
}
for (1 .. $count ) {
my $result = qx(~/bin/roland $path);
say $result;
}
}
There is however data entry that must be done.
Each Treasure Class needs a table.
# treasure/class_a
- { file: treasure/a/cp }
- { file: treasure/a/sp }
- { file: treasure/a/ep }
- { file: treasure/a/gp }
- { file: treasure/a/pp }
- { file: treasure/a/gems }
- { file: treasure/a/jewelry }
- { file: treasure/a/magic }
Then each file
# treasure/a/cp
dice: 1d100
results:
1-25:
dice: 2d6
results:
2: 1000 cp
3: 1500 cp
4: 2000 cp
5: 2500 cp
6: 3000 cp
7: 3500 cp
8: 4000 cp
9: 4500 cp
10: 5000 cp
11: 5500 cp
12: 6000 cp
26-100: ~
Snippet of the gems table.
93-94: "Violet garnet, [[1d20x50]]gp"
95:
dice: 1d100
results:
1-50: "Emerald, [[1d20x100]]gp"
51-100: "Fire opal, [[1d20x100]]gp"
96:
dice: 1d100
results:
1-50: "Opal, [[1d20x100]]gp"
51-100: "Oriental amethyst, [[1d20x100]]gp"
97:
dice: 1d100
results:
1-50: "Oriental topaz, [[1d20x100]]gp"
51-100: "Sapphire, [[1d20x100]]gp"
98:
dice: 1d100
results:
1-50: "Star ruby, [[1d20x100]]gp"
51-100: "Star sapphire, [[1d20x100]]gp"
Here is the jewelry table
# treasury/jewelry
- { file: treasure/jewelry_type }
- { file: treasure/jewelry_value }
Jewelry type table snippet
# treasury/jewelry_type
dice: 1d20
results:
1: anklet, no weight
2: armband, 1 lb
3: bracelet, no weight
4: bracer, 1 lb
5: broach, no weight
6: chain, 1 lb
7: circlet, no weight
8: comb, no weight
9: crown, 4 lb
Jewelry value table snippet
# treasury/jewelry
dice: 1d100
results:
1:
dice: 1d12
results:
1-6:
- " made of pewter, worth 1gp"
7-10:
- " made of bronze, worth 1gp"
11:
- " made of copper, worth 1gp"
12:
- " made of silver, worth 1gp"
What the application runs like on the command line.
$ ./roll_treasure gems
Carnelian, 90gp
$ ./roll_treasure jewelry
crown, 4 lb
made of electrum, worth 1,000gp
$ ./roll_treasure jewelry
armband, 1 lb
made of bronze, worth 3gp
$ ./roll_treasure jewelry
mask, 1 lb
made of copper set with gems, worth 400gp
Deep blue spinel, 700gp
And that is basically it.
My Assumptions
I am going to assume fluency with Perl in this post, along with
and understanding of YAML, JSON,
and CSV.
Intro
I've been going to Gary Con for many years now. It
has had several event submission and registration systems since
I started going.
In 2017 the convention started using TableTop Events(TTE)
for event management. With that came along an API. With an
API came a chance for automation and curiosity.
TTE has a decent event search mechanism along with the ability
to download a CSV (comma separated values) file of the events.
The API
It has a well documented and expansive API
The API is one way to grab more data than is listed in the event
search and CSV file.
There are some example clients that show how one could use the API
to gather various convention information.
I'm a sysadmin steeped in Perl so that is what I wrote
my example in, but there are example clients writing in
Javascript.
There is as a test api for your client if you write your
own.
ID please
Now we need to find the conventions ID in TTE.
At the top of the page is a link to Conventions. That page should upcoming conventions
as well as a search for conventions.
At the time of this writing Con of Champions
is in the event submission phase of things.
This one is rather special since it's geared towards helping raise money to keep TTE
going. Covid-19 is causing also sorts of financial problems for businesses. Hopefully
it can raise enough money to keep JT and crew operational until the pandemic is over
along with the dealing any lingering economic damage.
So do a search for Con of Champions.
Copy the link. Now, I'm using Linux so this is relatively simple. Go to the command line and run:
curl https://tabletop.events/conventions/con-of-champions 2>1 | grep "/api/convention"
This should return something like:
fetch_api : '/api/convention/105930EE-713D-11EA-AB57-B86D1B681414',
list_api : '/api/convention/105930EE-713D-11EA-AB57-B86D1B681414/event-days',
Event Data
Now that we have a con id we can use the browser to see what the
event data is like.
For Con of Champions using the following URL:
https://tabletop.events/api/convention/105930EE-713D-11EA-AB57-B86D1B681414/events
This will return JSON like the following:
{
"result" : {
"items" : [
{
"is_cancelled" : 0,
"more_info_uri" : "http://",
"host_showed_up" : 0,
"room_id" : "C3F7257A-735E-11EA-BA85-003D1B681414",
"special_requests" : null,
"event_number" : 32,
"date_created" : "2020-03-30 20:06:58",
"actual_price" : 0,
"max_tickets" : 100,
"price" : 0,
"convention_id" : "105930EE-713D-11EA-AB57-B86D1B681414",
"space_id" : "CC9EA888-735E-11EA-BA85-113D1B681414",
"type_id" : "9E78A594-7147-11EA-AB57-1A891B681414",
"view_uri" : "/conventions/con-of-champions/schedule/32",
"trashed" : 0,
"name" : "Just Three Hexes - Start RPG Campaigns Quickly!",
"room_name" : "Seminars",
"long_description_html" : null,
"wait_count" : 0,
"allow_schedule_conflicts" : 0,
"start_date" : "2020-05-23 15:00:00",
"max_hosts" : 1,
"attendee_head_count" : 0,
"sold_count" : 0,
"description" : "\"It takes just three hexes to start a campaign.\" You don't have to map out an entire world to get an awesome campaign rolling! In this seminar, I will show you my published \"3 Hexes\" technique for creating a fun campaign quickly!",
"sellable" : 1,
"startdaypart_id" : "9E84AAEC-7147-11EA-AC21-12DFCDE7307A",
"host_count" : 1,
"startdaypart_name" : "Saturday at 10:00 AM",
"alternatedaypart_id" : "9E9044C4-7147-11EA-AC21-12DFCDE7307A",
"space_name" : "C001",
"preferreddaypart_id" : "9E84AAEC-7147-11EA-AC21-12DFCDE7307A",
"custom_fields" : {
"Whatvirtualsystemwillbeusedtopresent" : "I will be using Zoom to present this seminar, as well as streaming it to my Twitch channel."
},
"age_range" : "teen",
"duration" : 60,
"submission_id" : "C5E9E018-72B2-11EA-A2B6-C13F1B681414",
"long_description" : null,
"is_scheduled" : 1,
"object_name" : "Event",
"object_type" : "event",
"id" : "02BEB31A-72C2-11EA-A2B6-58581B681414",
"available_count" : 100,
"date_updated" : "2020-03-31 14:54:57",
"claimable" : 0
},
],
"paging" : {
"total_pages" : 9,
"total_items" : 213,
"items_per_page" : 25,
"next_page_number" : 2,
"page_number" : 1,
"previous_page_number" : 1
}
}
}
This is everything for an event. Look to see if there is a
custom_fields in there. If there is make a note of them because
we will need to deal with them.
Some Organizing
So, we have enough info that we need to do a little data
wrangling. This can fit nicely into a config file. My current
format of choice is YAML
params:
url: https://tabletop.events
conid:
2020: B8477188-3D42-11E9-998D-F64533A48A88
username: USERNAME
password: PASSWORD
api_key: GET_YOUR_API_KEY
base_dir: /path/to/dump/data/YEAR
custom_fields:
- Whatvirtualsystemwillbeusedtoplay
Ok, this should be enough to let us write
our client to grab event data.
Heading to The Bit Mines
So, lets code up our client to do some data mining.
As a Linux sysadmin I do a lot of Perl programming so
that's what I'm going to do. Other languages are
left as an exercise for the reader.
First up, mostly boilerplate.
Have it use whatever perl my shell is using, make sure to
check if I'm being dumb so check things, and tell me
about it.
Load up the modules I need to do the things I want to
do. Thanks to those authors that have generously coded them up
and made available on the CPAN.
Also, turn on new Perl things, and use a really new Perl
thing and don't complain about it.
#!/usr/bin/env perl
use strict;
use warnings;
use Getopt::Long;
use POSIX qw(strftime);
use YAML qw(LoadFile);
use Wing::Client;
use Text::CSV;
use v5.30;
use experimental qw(signatures);
Next chunk, is setting STDOUT to autoflush output.
Then setup some variables for the options I want
to use and some error checking of them.
$| = 1;
my $config_file;
my $conid_year;
GetOptions (
"config|c=s" => \$config_file,
"year|y=i" => \$conid_year,
)
or die ("Error in command line arguments\n");
if ( $conid_year < 2020 ) {
say q(Invalid year, must be greater than 2019);
exit(0);
}
This is the bulk of "what to do".
Create a time stamp to give files we generate a useful name,
load our config file, and create our Wing object so we can hit
up the TTE API.
We move on to do some prep work to prime the pump before we dive
in and page through all of the event data there might be.
Finally, dump that event data into a csv file and exit the program
with an appropriate exit code.
say q(Start things up);
our $time_stamp = strftime("%Y-%m-%d_%H-%M-%S", localtime(time) );
my ($config) = startup($config_file, $time_stamp);
say q(Create Wing client object);
my ($wing, $session) = get_wings($config);
my $page_number = 1;
say q(Get Data);
print q( fetching page : ), $page_number;
my ($data) = get_data($wing, $session, $page_number);
my $events_ref;
map { push(@$events_ref, $_) } $data->{items}->@*;
($events_ref) = page_through_events($wing, $session, $events_ref);
make_csv_file($config, $events_ref);
exit(0);
But wait, there's more, I need to go through all the subroutines called.
Just reading in our YAML file and then replacing the YEAR placeholder
with the supplied year
sub startup ($config_file, $time_stamp) {
say q(Read config_file);
my ($config) = LoadFile($config_file);
$config->{base_dir} =~ s/YEAR/$conid_year/;
return($config);
}
Create the object to talk with the API. Using our config
file to provide all the info it needs.
sub get_wings ($config) {
my $wing = Wing::Client->new(uri => $config->{url});
my $session = $wing->post('session',
{ username => $config->{username},
password => $config->{password},
api_key_id => $config->{api_key}
},
);
return($wing, $session);
}
Here's the heart of things. Calling the API, getting the event data,
and then passing that data back.
sub get_data ($wing, $session, $page_number) {
my $conid = $config->{conid}{$conid_year};
my $query_string = qq(/api/convention/$conid/events);
my $data;
$data = $wing->get($query_string, {
session_id => $session->{id},
_page_number => $page_number,
_items_per_page => 100,
});
return($data);
}
Now we gotta go through however many pages of data there are.
sub page_through_events ($wing, $session, $events_ref) {
my $next_page_number = $data->{paging}{next_page_number};
my $total_pages = $data->{paging}{total_pages};
for my $page_number ( $next_page_number ... $total_pages ) {
print qq( $page_number);
($data) = get_data($wing, $session , $page_number);
map { push(@$events_ref, $_) } $data->{items}->@*;
}
say q();
return($events_ref);
}
Once we have all that event data, dump it into a file format that is
a bit more usable.
Create a file name and file handle to write to that file.
The $csv object is set to use binary so it handles anything in the parsing
that might be binary, otherwise it's expecting roughly the ASCII character
set. Unexpected things might happen othwerwise.
Get the headers to use in the first row of the file and print that
to the csv file. Check to see if there are any errors printing to the file.
I added this because I initially didn't have binary parsing turned on and I spent
way too much time figuring out where 15 events disappeared from the gathering of
them to the printing of them.
Then, loop through the rest of the data.
sub make_csv_file ($config, $events_ref) {
say q(make event csv file);
my $csv_file = $config->{base_dir} . qq(/$time_stamp-events.csv);
open my $fh, '>', $csv_file;
$fh->autoflush();
my $csv = Text::CSV->new({ binary => 1});
$csv->eol ("\n");
my ($header_ref) = get_headers($config, $events_ref);
my ($status) = $csv->print($fh, $header_ref);
check_csv_status($csv, $status, $header_ref);
$csv->SetDiag(0);
my $count = 1;
EVENT:for my $event ( $events_ref->@* ) {
my ($event_info_ref) = get_event_info($event, $config);
my ($status) = $csv->print($fh, $event_info_ref);
check_csv_status($csv, $status, $event_info_ref);
$csv->SetDiag(0);
$count += 1;
}
}
Sort the keys from the hash that event data is kept in.
If there happens to be a custom_fields deal
with it, otherwise add to the headers array.
sub get_headers ($config, $events_ref) {
my @headers;
for my $header ( sort keys $events_ref->[0]->%* ) {
if ( $header eq q(custom_fields) ) {
for my $custom_field ( $config->{custom_fields}->@* ) {
push(@headers, $custom_field);
}
}
else {
push(@headers, $header);
}
}
return(\@headers);
}
Just some mundane error checking to see why something might not have
printed to the csv file. If so, die so you can figure out why.
sub check_csv_status ($csv, $status, $event_info_ref) {
unless ( 1 == $status ) {
my ($cde, $str, $pos, $rec, $fld) = $csv->error_diag();
say q( csv print error);
say qq( cde : $cde);
say qq( str : $str);
say qq( pos : $pos);
say qq( rec : $rec);
say qq( fld : $fld);
for my $field ( $event_info_ref->@* ) {
say $field;
}
exit(0);
}
}
For each event go through the hash. If nothing unexpected happens stuff it
into the events array ref. The custom_fields key needs to be expanded with any
additional fields that it brings along. Fields matching description
might have newlines that will really mess up a csv file.
sub get_event_info ( $event, $config ) {
my $event_array_ref;
for my $event_key ( sort keys $event->%* ) {
if ( $event_key eq q(custom_fields) ) {
($event_array_ref) = handle_custom_fields($event, $config, $event_array_ref);
}
elsif ( $event_key =~ m/description/ ) {
($event_array_ref) = escape_newlines($event_key, $event, $event_array_ref);
}
else {
my $value = $event->{$event_key};
if ( ! defined $value ) {
$value = q();
push(@$event_array_ref, q());
}
push(@$event_array_ref, $value);
}
}
return ($event_array_ref);
}
See what the custom_fields entry in the config file needs to add to the events array.
sub handle_custom_fields ($event, $config, $event_array_ref) {
for my $custom_field ( $config->{custom_fields}->@* ) {
my $field = $event->{custom_fields}{$custom_field};
push(@$event_array_ref, $field);
}
return($event_array_ref);
}
Get rid of newlines in a field. It messes with the formatting
that was submitted by the person running the event, but that's life.
sub escape_newlines ($event_key, $event, $event_array_ref) {
my $field;
if ( defined $event->{$event_key} ) {
$event->{$event_key} =~ s/\R|\n//g;
}
push(@$event_array_ref, $event->{$event_key});
return($event_array_ref);
}
And that's it for now.
If you think you need more event data than TTE makes available in their csv file for
a convention...well now you can go digging.
Intro
A long term project of mine was to find an easy
way to import character sheets into Roll20.
There are tools for D&D 5e and such but nothing
for my game of choice, Astonishing Swordsmen and
Sorcerers of Hyperborea. Hyperborea for short.
Recently I did find an API using tool that would
work. However, that requires you to have a paid
account. Which I do. I still might use it.
However, I did find something that mostly works,
Roll20 Character Import/Export.
I do have a program
that can take a yaml file
and populate a form fillable pdf. Taking that
and banging my head against the wall for a few
weeks. With some help from a friend to
understand some javascript I was able to get it
working as much I really need it to.
The Base Character Sheet
So, I'm trying out the idea of keeping character
info a yaml or markdown file.
I've settled on something like this:
ST: 17
DX: 10
CN: 14
IN: 17
WS: 12
CH: 12
class: fire lord
level: 5
Race: Kelt
Gender: female
Age: 17
HP: 45
XP: 45,000
Gear:
- <starter_pack>
- Hunting horn
- leather mask
- <hm>dagger x3[w]
- <a>small shield
Magic:
- Hand Axe +2
Spells:
- Flaming Missile
- Flame Blade
- Fireball
This has some syntax in it that I built up as I was
making my pc generator for Hyperborea.
There are many table lookups and such. I then dump the data into
a Form Data Forma, (FDF) that I can use
to create a Hyperborea character sheet.
I can take data from one format and munge into another.
Now to think about the next data format.
Roll20 Character Sheet
Roll20 has a lot of character sheets you can use in your
game. A lot of them,
you can even submit yours to be added to the repo.
To figure out what Roll20 has named each of the various attributes
you will need to get a copy of your target character sheet. You can
either clone their repo or you can find your character sheet in the repo
and get that copy.
For HTML munging and extraction I reach for Mojo::DOM.
It doesn't take much to get what I want:
my ($html) = join('',<>);
my $dom = Mojo::DOM->new($html);
say $dom->find('[name]')->map(attr => 'name')->join("\n");
It's just using CSS selectors so it shouldn't be too hard
to translate that to the language of your choice.
I then created a mapping to go from my program (centered around an FDF)
to the roll20 names:
"Character Name": character_name
"Class": class
Level: level
Align: align
ST: ST
"ST Attack Mod": meleehitbonus
"ST Damage adj": meleedmgbonus
"Test of ST": testst
"Feat of ST": featst
Next is the hard part.
Import Character data into Roll20 Character Sheet
I did find something that was relatively easy...ish to
import that data, ChatSetAttr.
However, most folks don't pay for roll20. I use it enough
and I like to pay for useful things like it, but I still
wanted a way to get character sheet data imported.
To be honest...I was looking at the problem off and on
for probably a year before I found this Firefox plugin.
I have manually entered the character data in a test
campaign I use for ideas I want to try out. I mention
this because my initial attempts to import a character
that I hadn't manually imported, nor used the ChatSetAttr
API didn't work.
Eventually I hit upon exporting a character sheet that I had
filled out manually. This gave me the format to import.
{
"schema_version": 1,
"name": "barb_test",
"avatar": "",
"bio": "",
"attribs": [
{
"name": "reactionmod",
"current": "1",
"max": "",
"id": "-M4dusSQdUOIdxhCvhKD"
},
I was then stuck on that id.
I went to the roll20 forums and was pointed to some
code.
This code creates a sort of UUID. The main thrust of it being something like:
return function() {
var c = (new Date()).getTime() + 0, d = c === a;
a = c;
for (var e = new Array(8), f = 7; 0 <= f; f--) {
e[f] = "-0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz".charAt(c % 64);
c = Math.floor(c / 64);
}
A revelation
So, now I needed to translate those functions into my weapon of choice, Perl.
A friend helped me with the translation so I could generate uuid's in the format
that roll20 understands.
That bit of help broke open the damn...or...was just enough help to smash my
head through the wall I was hitting against.
The repeating items problem
Being able to import basic player info was great.
Now I had to tackle what are in the html as repeating items. Things like gear,
abilities, weapon info, spells, etc.
This was mostly a puzzle for my code. The uuid code does have something explicit
for repeating items uuids.
{
"name": "repeating_melee_-M4dusTPpXLZyuX3dipz_meleeweaponname",
"current": "dagger",
"max": "",
"id": "-M4dusTP3-Ipr2NBQx-P"
},
{
"name": "repeating_melee_-M4dusTPpXLZyuX3dipz_meleeclass",
"current": "1",
"max": "",
"id": "-M4dusTQdb3JG38lovQM"
},
{
"name": "repeating_melee_-M4dusTPpXLZyuX3dipz_meleeatkrate",
"current": "1/1",
"max": "",
"id": "-M4dusTQEEylJV5QjKro"
},
{
"name": "repeating_melee_-M4dusTPpXLZyuX3dipz_meleeatkmod",
"current": "0",
"max": "",
"id": "-M4dusTQ7yLYX5ddp6oD"
},
{
"name": "repeating_melee_-M4dusTPpXLZyuX3dipz_meleedamage",
"current": "1d4+1",
"max": "",
"id": "-M4dusTRgK3BjoBRFvle"
},
In the above snippet, this represents the info for a melee weapon. It's name,
weapon close, attack rate, attack modifiers, and damage. There is a a field
for notes which I didn't enter for this weapon.
Each html attribute name is of the format, "repeating_melee_ROWID_attrname".
ROWID is replaced with a row id that is similar to the "normal" uuid. Each
item in the same line has the same ROWID but different "id"s.
That is basically it.
I am still going through and adding things but now it's just an iterative process.
I update the code, fix the syntax errors in my code because I mostly do this
at the end of the day and I have very little brain for such task, and then do
and import to see what it looks like.
So far the only thing that isn't really working is the equipment list. I'm ok
with that. It can be added manually if needed. These programs take a lot of the
pain out of this.
TL;DR
- start with a beginning data format
- munge to a target format
- add another target format
- extract HTML attribute names from an html file
- use those names to map from initial format to new target format
- create properly formatted json file
- test import
- check that it looks ok
- lather
- rinse
- repeat as needed
Fin
And with that...I need to go to bed, maybe watch some WestWorld. Good night y'all.